Word vectors – also called word embeddings – are mathematical descriptions of individual words such that words that appear frequently together in the language will have similar values. In this way we can mathematically derive context. As mentioned above, the word vector for “lion” will be closer in value to “cat” than to “dandelion”.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content Semantic similarity includes “is a” relations. For example, “car” is similar to “bus“
Key takeaways from this post:
- Feature Extraction from Text
- Count Vectorizer
- Term Frequency
- Term Frequency-Inverted Document Frequency tf-idfVectorizer
- word2vec and Semantic Similarity
- Arithmetic operations on word vectors
1. Count Vectorizer
Simply count the occurrence of each word in the document to map the text to a number.

While counting words is helpful, it is to keep in mind that longer documents will have higher average count values than shorter documents, even though they might talk about the same topics. Hence counting words is not enough to describe the features of the text.
It simply works like if count is more assign more weight.
2. Term Frequency tf(t,d)
Divide the number of occurrences of each word in a document by the total number of words in the document

Even term frequency tf(t,d) alone isn’t enough for the thorough feature analysis of the text. Let’s understand this with an example.
Consider the frequently occurring words like “is”, “am”, “are” .. “the”..etc.
In this case the term frequency method will tend to incorrectly emphasize the documents which happen to use the words like “the” more frequently. And it will give less weight to the more meaningful words like “eCommerce”, “red”, “lion” etc. which might be occurring less frequently in the document compare to the word “the”.
These more frequently occurring words are known as STOP WORDS.
Again we have something better than alone term frequency known as the tf-idfVectorizer which will understand in the next method.
3. tf-idfVectorizer
Another refinement on top of tf is to downscale weights for words that occur in many documents in the corpus and are therefore less informative than those that occur only in a smaller portion of the corpus and are more informative.
This downscaling is called tf–idf for “Term Frequency times Inverse Document Frequency”.
Inverse Document Frequency idf: It is the logarithmic scaled inverse fraction of the documents that contains the term.

So the Inverse Document Frequency factor reduces the weight of the terms which occur very frequently in many documents and increases the weight of the important terms which occur rarely or in few documents.
you can refer https://ashutoshtripathi.com/2020/09/02/numerical-feature-extraction-from-text-nlp-series-part-6/ for the python code for the above methods.
In this post we will focus more on the word2vec technique.
Word2vec
- Word2vec groups the vector of similar words together in the vector space.
- That is it detects similarities mathematically.
- Given enough data, usage and contexts, word2vec can make highly accurate guesses about a word’s meaning based on past appearances.
- Those guesses can be used to establish a word’s association with other words eg. “man” is to “boy” what “woman” is to “girl”.
- Each word is represented by a vector and in spaCy each vector has 300 dimensions [300 different properties associated, helpful while similarity matching]
Vector Arithmetic
We can also perform the vector arithmetic with the word vectors.
outputVector = king – man + woman
This creates the new vector “outputVector” that we can then attempt to find most similar vectors to.
[outputVector should be closest to vector queen???]


Tf-idf is a scoring scheme for words – that is a measure of how important a word is to a document.
From a practical usage standpoint, while tf-idf is a simple scoring scheme and that is its key advantage, word embeddings or word2vec may be a better choice for most tasks where tf-idf is used, particularly when the task can benefit from the semantic similarity captured by word embeddings (e.g. in information retrieval tasks)
Lets realize the above concept with spacy.
Installing Larger spaCy Models
Up to now we’ve been using spaCy’s smallest English language model, en_core_web_sm (35MB), which provides vocabulary, syntax, and entities, but not vectors. To take advantage of built-in word vectors we’ll need a larger library. We have a few options:
en_core_web_md (116MB) Vectors: 685k keys, 20k unique vectors (300 dimensions)
or
en_core_web_lg (812MB) Vectors: 685k keys, 685k unique vectors (300 dimensions)
If you plan to rely heavily on word vectors, consider using spaCy’s largest vector library containing over one million unique vectors:
en_vectors_web_lg (631MB) Vectors: 1.1m keys, 1.1m unique vectors (300 dimensions)
For our purposes en_core_web_md should suffice.
From the command line (you must run this as admin or use sudo):
activate spacyenv if using a virtual environment
python -m spacy download en_core_web_mdpython -m spacy download en_core_web_lg optional librarypython -m spacy download en_vectors_web_lg optional library
If successful, you should see a message like:
**Linking successful**
C:\Anaconda3\envs\spacyenv\lib\site-packages\en_core_web_md –>
C:\Anaconda3\envs\spacyenv\lib\site-packages\spacy\data\en_core_web_md
You can now load the model via spacy.load(‘en_core_web_md’)
Of course, we have a third option, and that is to train our own vectors from a large corpus of documents. Unfortunately this would take a prohibitively large amount of time and processing power.
Word Vectors
Word vectors – also called word embeddings – are mathematical descriptions of individual words such that words that appear frequently together in the language will have similar values. In this way we can mathematically derive context. As mentioned above, the word vector for “lion” will be closer in value to “cat” than to “dandelion”.
Vector values
So what does a word vector look like? Since spaCy employs 300 dimensions, word vectors are stored as 300-item arrays.
Note that we would see the same set of values with en_core_web_md and en_core_web_lg, as both were trained using the word2vec family of algorithms.


What’s interesting is that Doc and Span objects themselves have vectors, derived from the averages of individual token vectors. This makes it possible to compare similarities between whole documents.
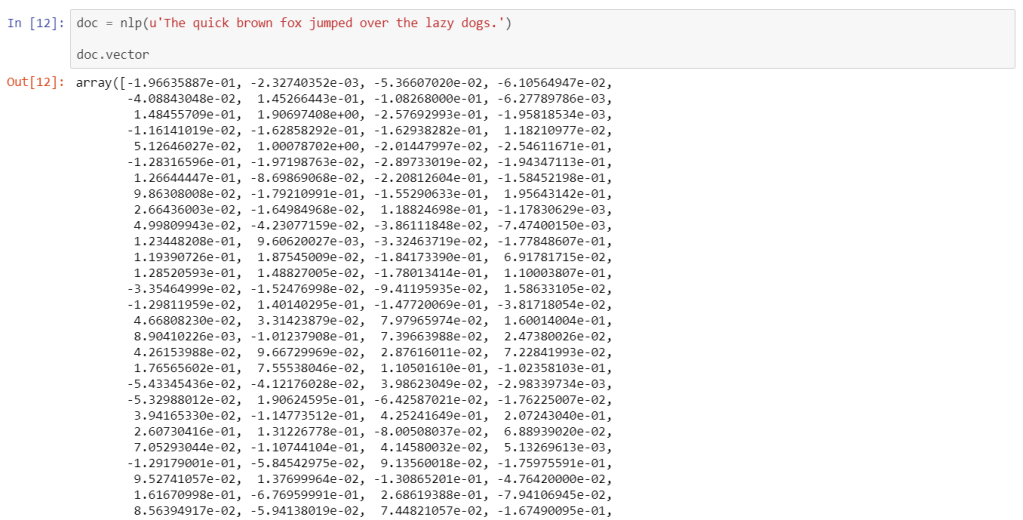


Identifying similar vectors
The best way to expose vector relationships is through the .similarity() method of Doc tokens.
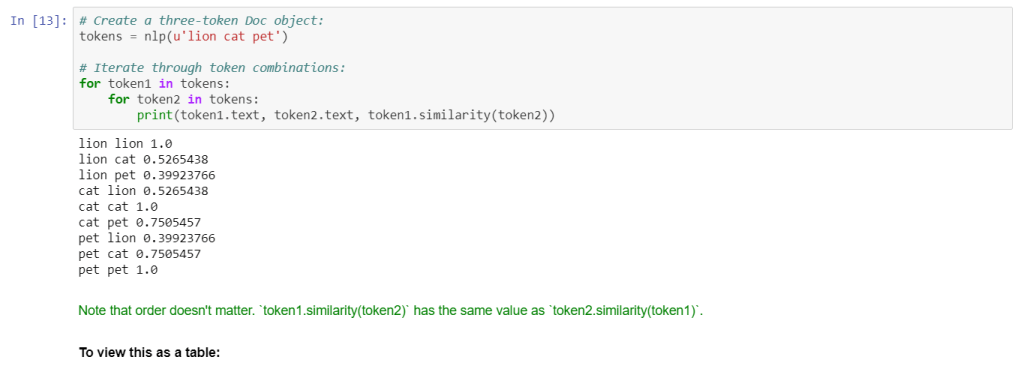





This is all about the word2vec using spacy. if anything is not clear please feel free to ask using comment, I would love to answer.
Thank you.

can we find words similar to a particular word in a document. For example: I wanted to find a word similar to “travel” in a given document. And analyse where all the subject travelled?
LikeLiked by 1 person
yes, you can use word similarity to do this.
https://rapidapi.com/pedram.ataee/api/word-similarity
LikeLike
thank you for the response. That helps!
LikeLike
We absolutely love your blog and find many of your post’s to be just what I’m looking for. can you offer guest writers to write content available for you? I wouldn’t mind creating a post or elaborating on many of the subjects you write concerning here. Again, awesome site!
LikeLike
Thank you very much for this clear article
LikeLike
can we compare 2 articles using spacy
LikeLike
Yes we can compare 2 articles using spacy.
LikeLike