As the name suggests, Conditional Probability is the probability of an event under some given condition. And based on the condition our sample space reduces to the conditional element.
For example, find the probability of a person subscribing for the insurance given that he has taken the house loan. Here sample space is restricted to the persons who have taken house loan.
To understand Conditional probability, it is recommended to have an understanding of probability basics like Mutually Exclusive and Independent Events, Joint, Union and Marginal Probabilities and Probability vs Statistics etc. In case you want to revise those concepts, you can refer those here Probability Basics for Data Science.
Wiki Definition:
In probability theory, conditional probability is a measure of the probability of an event occurring given that another event has occurred. If the event of interest is A and the event B is known or assumed to have occurred, “the conditional probability of A given B”, or “the probability of A under the condition B”, is usually written as P(A | B), or sometimes PB(A) or P(A / B) —Wikipedia
Now the question may come like why use conditional probability and what is its significance in Data Science?
Let’s take a real-life example. Probability of selling a TV on a given normal day may be only 30%. But if we consider that given day is Diwali, then there are much more chances of selling a TV. The conditional Probability of selling a TV on a day given that Day is Diwali might be 70%. We can represent those probabilities as P(TV sell on a random day) = 30%. P(TV sell given that today is Diwali) = 70%.
So Conditional Probability helps Data Scientists to get better results from the given data set and for Machine Learning Engineers, it helps in building more accurate models for predictions.
Let’s deep dive into it more:
Following table contains the different age group peoples who have defaulted and not defaulted on Loans.

Converting the above table into probabilities
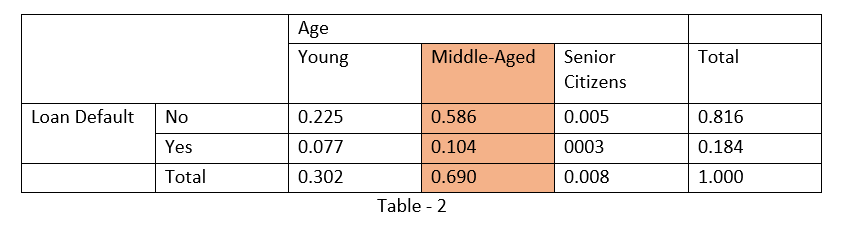
So if we are able to convert the data given in question, in tabular form, then sample space will get reduced to either the full column or a complete row and rest of the sample space becomes irrelevant.
What is the probability that a person will not default on the loan given he/she is middle-aged?
P(No | Middle-Aged) = 0.586/0.690 = 0.85 [referring table – 2, probability form data]
P(No|Middle Aged ) = 27368/32219 = 0.85 [referring table -1, normal numbered data]
If you notice, it is very clear that in the numerator it is the Joint Probability that is the Probability of a person not defaulting on the loan and also the person is middle-aged.
And in the denominator, it is the Marginal probability that is the Probability of a Person being middle-aged.
Hence we can also define the Conditional probability as the ratio of Joint probability to the Marginal probability.
P(A|B) = P(A and B)/P(B)
Again let’s ask the question little differently by changing the order as below.
What is the probability that a person is middle-aged given he/she has not defaulted on the loan?
Now see, sample space has changed to the colored row that is persons who have not defaulted on Loan.

P(Middle-Aged | No) = 0.586/0.816 = 0.72 (Order Matters)
Now did you notice something again, probability is changed by changing the order of the events.
Hence in Conditional probability order matters.
Conditional Probability Visualization using Probability Tree

Explanation:
I have tried to explain each branch logic within the tree itself. Now let’s dive into the questions which will explain the importance of probability tree in calculating the conditional probabilities.
P(Young and No)?
- Use standard conditional probability formula:
- P(Young | No) = P(Young and No)/P(No) which implies:
- P(Young and No) = P(Young | No) * P(No)
- By Probability tree, we know the probability of P(Young | No) = 0.275 and P(No) = 0.816.
- Now see right side all probabilities values are known, hence put them in above equation and we will get the desired probability.
- P(Young and No) = 0.275 * 0.816 = 0.2244 = ~0.225
P(No and Young)? (Order is changed)
- P(No and Young) = P(Young and No) = 0.225 [same as above]
- In Joint probability order does not matter
P(Young)?
- Look at all the branches associated with Young (ending with Young) and take Sum of Products of probability values within branch
- Which means
- P(Young) = 0.816 * 0.275 + 0.184 * 0.419 = 0.301496 = ~ 0.302
P(No)?
- P(No) = 0.816 (Directly from the tree)
P(Young | No)?
- P(Young | No) = p(Young | Not a loan defaulter) = 0.275 [see the tree]
P(No | Young)? [Order changed]
- P(No | Young) = P(Young and No)/P(Young) [we have already calculate right side probabilities in above calculation]
- P(No | Young) = 0.225/0.302 = 0.745
Now let’s explore the standard conditional probability formula.
From conditional probability we know that
- P(A|B) = P(A and B)/P(B)
- P(A and B) = P(B) * P(A|B) ————–[1]
Similarly
- P(B|A) = P(B and A)/P(A) = P(A and B)/P(A) [I n Joint Probability order does not matter]
- P(A and B) = P(A) * P(B|A) ———[2]
From equation [1] and [2],
- P(B) * P(A|B) = P(A) * P(B|A)
- P(A|B) = P(A) * P(B|A) / P(B) [also known as Bayes’ Theorem]
Now if we want to find the P(No | Young). Then we can use the above derived formula directly. Because P(Young | No) as well as P(Young) values will get from probability tree and putting in above formula will give the result. we will learn more on Bayes’ Theorem in next post.

Explanation
I have tried to explain the given problem using the probability tree as shown above. However if anything is not clear, I am writing down what is given and what is asked. And how to calculate what is being asked.
P(A becoming the CEO) = 0.2, P(B becoming the CEO) = 0.3, P(C becoming the CEO) = 0.4.
From the question, we need to deduce correctly that later probabilities are all conditional probabilities. This is the trick here. As they will only take beneficial decisions, once they become the CEO. Hence we should read those probabilities as below
- P(Taking beneficial Decisions | A is selected as CEO) = 0.5
- P(Taking beneficial Decisions | B is selected as CEO) = 0.45
- P(Taking beneficial Decisions | C is selected as CEO) = 0.6
So now P(having beneficial Decisions) is nothing but the total probability. Hence will calculate the Sum of Products of each branch probability values associated. (branch with beneficial decisions, see the tree). Hence:
P(having beneficial decisions) = 0.2*0.05 + 0.3*0.45 + 0.4*0.6 = 0.475

Explanation
- P(emails come in account 1) = 0.70
- P(emails come in account 2) = 0.20
- P(emails come in account 3) = 0.10
- P(email is spam | delivered to account 1) = P(Spam | account 1) = 0.01
- P(email is spam | delivered to account 2) = P(Spam | account 2) = 0.02
- P(email is spam | delivered to account 3) = P(Spam | account 3) = 0.05
Using Bayes’ Theorem,
P(Account 2 | email is Spam) = P(Account 2) * P(Spam | Account 2)/P(Spam)
Numerator values are known, Denominator P(Spam) is know ans total probability and calculated by taking the Sum of Products of Each Branch probability values [branches ending with Spam see the tree].
P(Spam) = 0.70*0.01 + 0.20*0.02 + .10*0.05
P(Account 2) = 0.20 [given in question]
P( Spam | Account 2) = 0.02 [given in question]
Putting everything together, P( Account 2 | email is Spam) = 0.20*0.02/( 0.70*0.01 + 0.20*0.02 + .10*0.05)
Answer: P( Account 2 | email is Spam) = 0.25
So that is all about Conditional Probability for data Science. In next posts I will be writing Bayes’ Theorem in detail and Probability Distributions which will complete the Probability for Data Science Series.
Feel free to contact us for more details and discussions.

Very well explained. Keep it up 🤪
LikeLike