Principal Component Analysis or PCA is a widely used technique for dimensionality reduction of the large data set. Reducing the number of components or features costs some accuracy and on the other hand, it makes the large data set simpler, easy to explore and visualize. Also, it reduces the computational complexity of the model which makes machine learning algorithms run faster. It is always a question and debatable how much accuracy it is sacrificing to get less complex and reduced dimensions data set. we don’t have a fixed answer for this however we try to keep most of the variance while choosing the final set of components.
In this article, we will be discussing the step by step approach to achieve dimensionality reduction using PCA and then I will also show how can we do all this using python library.
Steps Involved in PCA
- Standardize the data. (with mean =0 and variance = 1)
- Compute covariance matrix of dimensions.
- Obtain the Eigenvectors and Eigenvalues from the covariance matrix (we can also use correlation matrix or even Single value decomposition, however in this post will focus on covariance matrix).
- Sort eigenvalues in descending order and choose the top k Eigenvectors that correspond to the k largest eigenvalues (k will become the number of dimensions of the new feature subspace k≤d, d is the number of original dimensions).
- Construct the projection matrix W from the selected k Eigenvectors.
- Transform the original data set X via W to obtain the new k-dimensional feature subspace Y.
Let’s import some of the required libraries and also the Iris data set which I will use to explain each of the points in details.
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.decomposition import PCA from sklearn.preprocessing import standardScaler %matplotlib inline
df = pd.read_csv(
filepath_or_buffer='https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',
header=None,
sep=',')
df.columns=['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'class']
print(df.isnull().values.any())
df.dropna(how="all", inplace=True) # drops the empty line at file-end
#if inplace = False then we have to assign back to dataframe as it is a copy
#df = df.some_operation(inplace=False)
#No need to assign back to dataframe when inplace = True
#df.some_operation(inplace=True)
#Print Last five rows.
df.tail()

Separate the Target column that is the class column values in y array and rest of the values of the independent features in X array variables as below.
X = df.iloc[:,0:4].values y = df.iloc[:,4].values

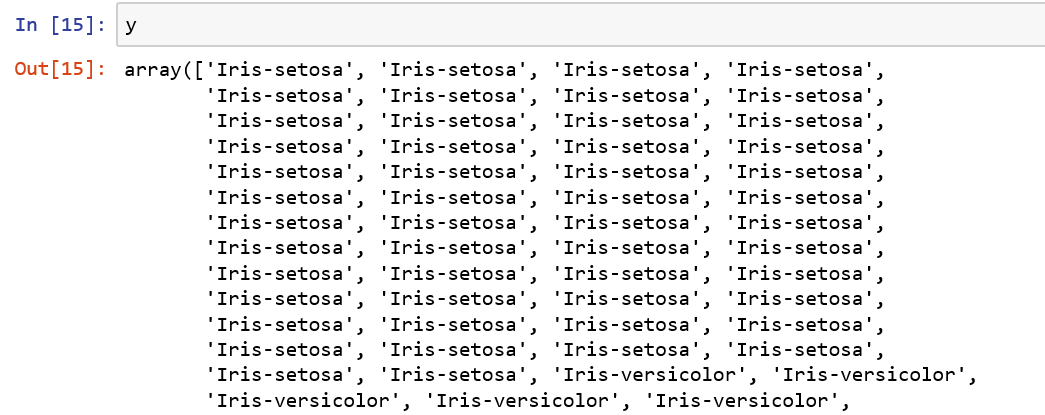
Iris data set is now stored in the form of a 150×4 matrix where the columns are the different features, and every row represents a separate flower sample. Each sample row x can be pictured as a 4-dimensional vector as we can see in the above screenshot of x output values.
Now let’s understand each of the point in detail.

1. Standardization
When there are different scales used for the measurement of the values of the features, then it is advisable to do the standardization to bring all the feature spaces with mean = 0 and variance = 1.
The reason why standardization is very much needed before performing PCA is that PCA is very sensitive to variances. Meaning, if there are large differences between the scales (ranges) of the features, then those with larger scales will dominate over those with the small scales.
For example, a feature that ranges between 0 to 100 will dominate over a feature that ranges between 0 to 1 and it will lead to biased results. So, transforming the data to the same scales will prevent this problem. That is where we use standardization to bring the features with mean value 0 and variance 1.
So here is the formula to calculate the standardized value of features:

In this article, I am using the Iris data set. Although all features in the Iris data set are measured in centimeters, Still I will continue with the transformation of the data onto the unit scale (mean=0 and variance=1), which is a requirement for the optimal performance of many machine learning algorithms. Also, it will help us to understand how this process works.
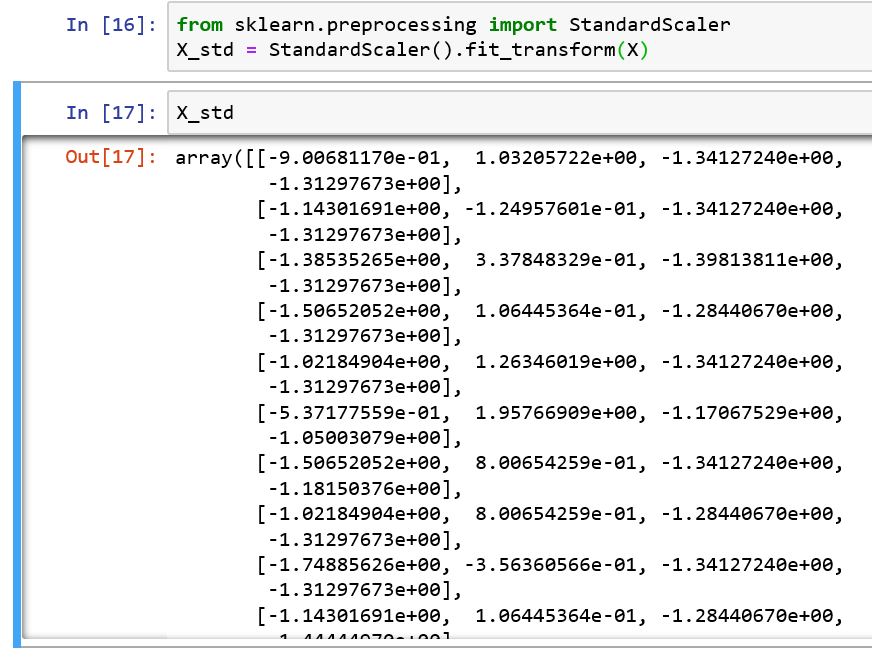
from sklearn.preprocessing import StandardScaler X_std = StandardScaler().fit_transform(X)
In the output screen shot below you see that all X_std values are standardized in the range of -1 to +1.
2. Eigen decomposition – Computing Eigenvectors and Eigenvalues
The eigenvectors and eigenvalues of a covariance (or correlation) matrix represent the “core” of a PCA:
- The Eigenvectors (principal components) determine the directions of the new feature space, and the eigenvalues determine their magnitude.
- In other words, the eigenvalues explain the variance of the data along the new feature axes. It means corresponding eigenvalue tells us that how much variance is included in that new transformed feature.
- To get eigenvalues and Eigenvectors we need to compute the covariance matrix. So in the next step let’s compute it.
2.1 Covariance Matrix
The classic approach to PCA is to perform the Eigen decomposition on the covariance matrix Σ, which is a d×d matrix where each element represents the covariance between two features. Note d is the number of original dimensions of the data set. In Iris data set we have 4 features hence covariance matrix will be of order 4×4.
#mean_vec = np.mean(X_std, axis=0)
#cov_mat = (X_std - mean_vec).T.dot((X_std - mean_vec)) / (X_std.shape[0]-1)
#print('Covariance matrix \n%s' %cov_mat)
print('Covariance matrix \n')
cov_mat= np.cov(X_std, rowvar=False)
cov_mat

2.2 Eigenvectors and Eigenvalues computation from the covariance matrix
Here if we know concepts of Linear Algebra and how to calculate Eigenvectors and Eigenvalues of the matrix then this is going to be very helpful in understanding the below concepts. So it would be advisable to go through some of the basic concepts of Linear Algebra to have a deeper understanding of how everything works.
Here I am using numpy array to calculate Eigenvectors and Eigenvalues of the standardized feature space values as following:
cov_mat = np.cov(X_std.T)
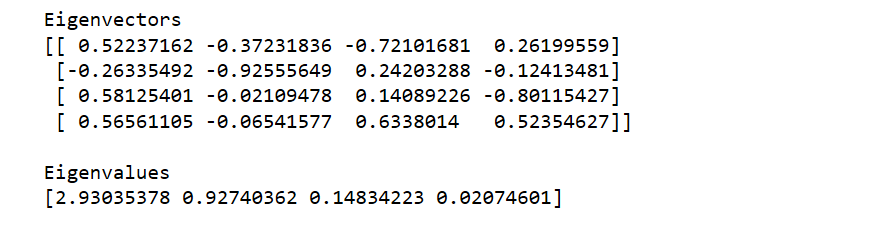
eig_vals, eig_vecs = np.linalg.eig(cov_mat)
print('Eigenvectors \n%s' %eig_vecs)
print('\nEigenvalues \n%s' %eig_vals)
2.3 Eigen Vectors verification
As we know that sum of square of each value in an Eigenvector is 1. So let’s see if it holds true which mean we have computed Eigenvectors correctly.
sq_eig=[]
for i in eig_vecs:
sq_eig.append(i**2)
print(sq_eig)
sum(sq_eig)
print("sum of squares of each values in an eigen vector is \n", 0.27287211+ 0.13862096+0.51986524+ 0.06864169)
for ev in eig_vecs:
np.testing.assert_array_almost_equal(1.0, np.linalg.norm(ev))

3. Selecting The Principal Components
- The typical goal of a PCA is to reduce the dimensionality of the original feature space by projecting it onto a smaller subspace, where the eigenvectors will form the axes.
- However, the eigenvectors only define the directions of the new axis, since they have all the same unit length 1.
So now the question comes that how to select the new set of Principal components. The rule behind is that we sort the Eigenvalues in descending order and then choose the top k features with respect to top k Eigenvalues.
The idea here is that by choosing top k we have decided that the variance which corresponds to those k feature space is enough to describe the data set. And by losing the remaining variance of those not selected features, won’t cost the accuracy much or we are OK to loose that much accuracy that costs because of neglected variance.
So this is the decision which we have to make based on the problem set given and also based on business case. There is no perfect rule to decide it.
Now let’s find out the Principal components using the following steps:
3.1 Sorting eigen values
In order to decide which Eigenvector(s) can be dropped without losing too much information for the construction of lower-dimensional subspace, we need to inspect the corresponding eigenvalues:
- The Eigenvectors with the lowest eigenvalues bear the least information about the distribution of the data; those are the ones can be dropped.
- In order to do so, the common approach is to rank the eigenvalues from highest to lowest in order to choose the top k Eigenvectors.
#Make a list of (eigenvalue, eigenvector) tuples
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:,i]) for i in range(len(eig_vals))]
print(type(eig_pairs))
#Sort the (eigenvalue, eigenvector) tuples from high to low
eig_pairs.sort()
eig_pairs.reverse()
print("\n",eig_pairs)
#Visually confirm that the list is correctly sorted by decreasing eigenvalues
print('\n\n\nEigenvalues in descending order:')
for i in eig_pairs:
print(i[0])

3.2 Explained Variance
- After sorting the eigenpairs, the next question is “how many principal components are we going to choose for our new feature subspace?”
- A useful measure is the so-called “explained variance,” which can be calculated from the eigenvalues.
- The explained variance tells us how much information (variance) can be attributed to each of the principal components.
tot = sum(eig_vals)
print("\n",tot)
var_exp = [(i / tot)*100 for i in sorted(eig_vals, reverse=True)]
print("\n\n1. Variance Explained\n",var_exp)
cum_var_exp = np.cumsum(var_exp)
print("\n\n2. Cumulative Variance Explained\n",cum_var_exp)
print("\n\n3. Percentage of variance the first two principal components each contain\n ",var_exp[0:2])
print("\n\n4. Percentage of variance the first two principal components together contain\n",sum(var_exp[0:2]))

4. Construct the projection matrix W from the selected k eigenvectors
- Projection matrix will be used to transform the Iris data onto the new feature subspace or we say new transformed data set with reduced dimensions.
- It is matrix of our concatenated top k Eigenvectors.
Here, we are reducing the 4-dimensional feature space to a 2-dimensional feature subspace, by choosing the “top 2” Eigenvectors with the highest Eigenvalues to construct our d×k-dimensional Eigenvector matrix W.
print(eig_pairs[0][1])
print(eig_pairs[1][1])
matrix_w = np.hstack((eig_pairs[0][1].reshape(4,1),
eig_pairs[1][1].reshape(4,1)))
#hstack: Stacks arrays in sequence horizontally (column wise).
print('Matrix W:\n', matrix_w)

5. Projection Onto the New Feature Space
In this last step we will use the 4×2-dimensional projection matrix W to transform our samples onto the new subspace via the equation Y=X×W, where the output matrix Y will be a 150×2 matrix of our transformed samples.
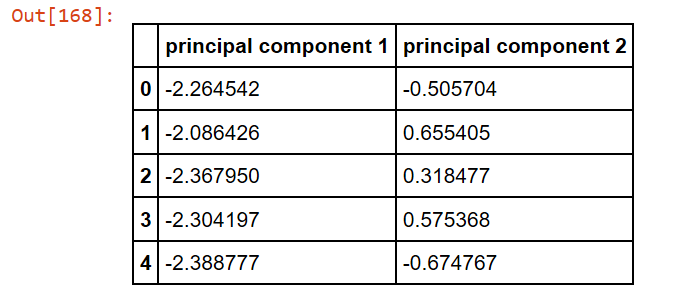
Y = X_std.dot(matrix_w)
principalDf = pd.DataFrame(data = Y
, columns = ['principal component 1', 'principal component 2'])
principalDf.head()
Now let’s combine the target class variable which we separated in the very beginning of the post.
finalDf = pd.concat([principalDf,pd.DataFrame(y,columns = ['species'])], axis = 1) finalDf.head()
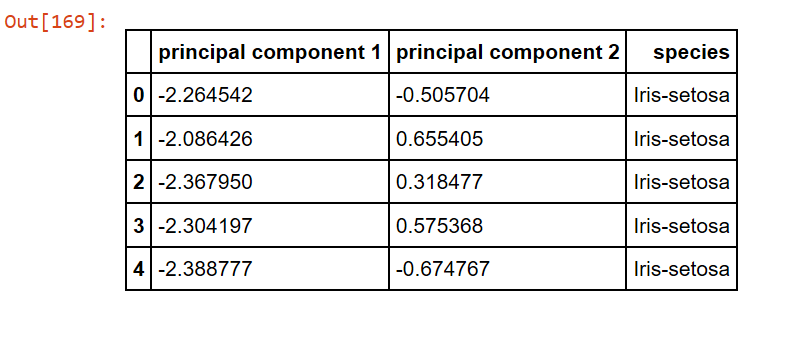
Visualize 2D Projection
Use a PCA projection to 2d to visualize the entire data set. You should plot different classes using different colors or shapes. Classes should be well-separated from each other.
fig = plt.figure(figsize = (8,5))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('Principal Component 1', fontsize = 15)
ax.set_ylabel('Principal Component 2', fontsize = 15)
ax.set_title('2 Component PCA', fontsize = 20)
targets = ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']
colors = ['r', 'g', 'b']
for target, color in zip(targets,colors):
indicesToKeep = finalDf['species'] == target
ax.scatter(finalDf.loc[indicesToKeep, 'principal component 1']
, finalDf.loc[indicesToKeep, 'principal component 2']
, c = color
, s = 50)
ax.legend(targets)
ax.grid()

Use of Python Libraries to directly compute Principal Components
Alternatively, there are direct libraries in python which computes the principal components directly and no need to do all the above computations. The above mentioned steps were to give you the understanding how everything works.
pca = PCA(n_components=2) # Here we can also give the percentage as a paramter to the PCA function as pca = PCA(.95). .95 means that we want to include 95% of the variance. Hence PCA will return the no of components which describe 95% of the variance. However we know from above computation that 2 components are enough so we have passed the 2 components.
principalComponents = pca.fit_transform(X_std)
principalDf = pd.DataFrame(data = principalComponents
, columns = ['principal component 1', 'principal component 2'])
principalDf.head(5) # prints the top 5 rows

finalDf = pd.concat([principalDf, finalDf[['species']]], axis = 1) finalDf.head(5)
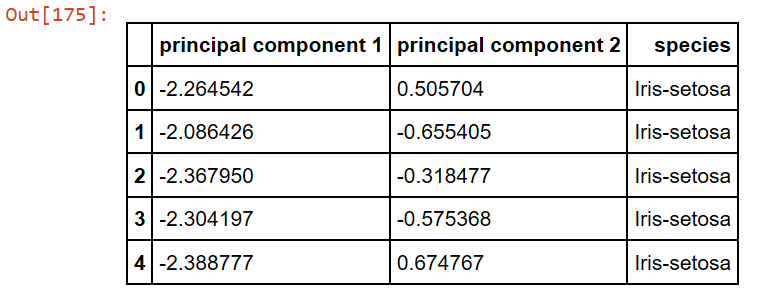
Together, the first two principal components contain 95.80% of the information. The first principal component contains 72.77% of the variance and the second principal component contains 23.03% of the variance. The third and fourth principal component contained the rest of the variance of the data set.
Next: How PCA speed-up the Machine Learning algorithms.
Feel free to contact us for more details and discussions.

6 comments