In this post, we will develop a classification model where we’ll try to classify the movie reviews on positive and negative classes. I have used different machine learning algorithm to train the model and compared the accuracy of those models at the end. you can keep this post as a template to use various machine learning algorithms in python for text classification. At the end we will validate the model by passing a random review to the trained model and understand the output class predicted by the model. You will learn how to create and use the pipeline for numerical feature extraction and model training together as a one function.
In this post I will be focusing on extracting the numerical features and then building a classification model. For text pre-processing steps you may refer the previous articles on NLP series:
- Spacy Installation and Basic Operations | NLP Text Processing Library | Part 1
- A Quick Guide to Tokenization, Lemmatization, Stop Words, and Phrase Matching using spaCy | NLP | Part 2
Data Source: http://www.cs.cornell.edu/people/pabo/movie-review-data/
Key takeaways from this article:
- Read in a collection of documents – a corpus
- Transform text into numerical vector data using a pipeline
- Create ML Pipelines with
- Naive Bayes
- Linear SVC
- Logistic Regression
- Random Forest
- XGBoost Classifier
- Fit/train the classifier
- Test the classifier on new data
- Evaluate performance
Start with importing the basic but very important libraries.
import numpy as np import pandas as pd
Load the data set
The data set contains the text of 2000 movie reviews. 1000 are positive, 1000 are negative, and the text has been pre-processed as a tab-delimited file.
df = pd.read_csv('/moviereviews.tsv', sep='\t')
df.head()

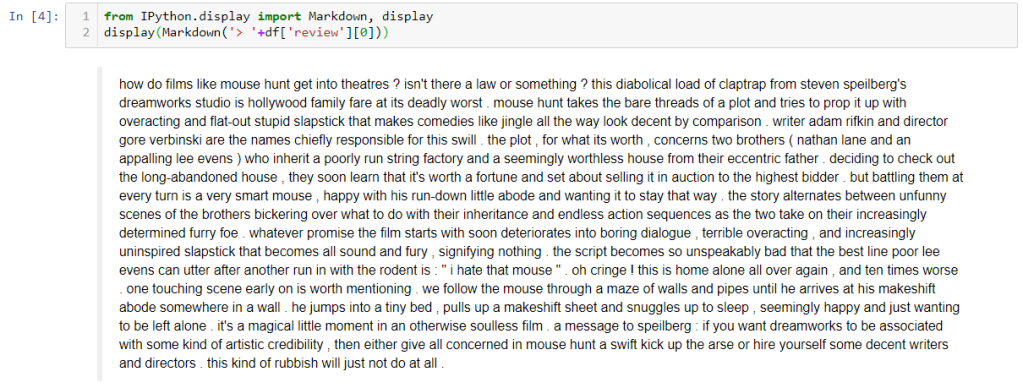
Take a look at a typical review. This one is labeled “negative”:
from IPython.display import Markdown, display
display(Markdown('> '+df['review'][0]))
Missing Values:
We have intentionally included records with missing data like NaN values and spaces. This happens in real world, eg. when a reviewer declined to provide a comment with their review.
- NaN records are efficiently handled with .isnull() and .dropna()
- Strings that contain only white space can be handled with .isspace(), .itertuples(), and .drop()
NaN values removal:
Check for the NaN values: df.isnull().sum()

35 records show NaN (this stands for “not a number” and is equivalent to None). These are easily removed using the .dropna() pandas function
df.dropna(inplace=True) len(df)

Empty Strings or Spaces Removal
Technically, we’re dealing with “white space only” strings. If the original .tsv file had contained empty strings, pandas .read_csv() would have assigned NaN values to those cells by default.
In order to detect these strings we need to iterate over each row in the DataFrame. The .itertuples() pandas method is a good tool for this as it provides access to every field. For brevity we’ll assign the names i, lb and rv to the index, label and review columns.
blanks = [] # start with an empty list
for i,lb,rv in df.itertuples(): # iterate over the DataFrame
if type(rv)==str: # avoid NaN values
if rv.isspace(): # test 'review' for whitespace
blanks.append(i) # add matching index numbers to the list
print(len(blanks), 'blanks: ', blanks)

Next we’ll pass our list of index numbers to the .drop() method, and set inplace=True to make the change permanent.
df.drop(blanks, inplace=True) len(df)

Great! We dropped 62 records from the original 2000. Let’s continue with the analysis.
Take a quick look at the label column:
df['label'].value_counts()

Split the data into train & test sets:
from sklearn.model_selection import train_test_split X = df['review'] y = df['label'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
Build pipelines to vectorize the data, then train and fit a model
Now that we have sets to train and test, we’ll develop a selection of pipelines, each with a different model.
from sklearn.pipeline import Pipeline from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB from sklearn.svm import LinearSVC from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier from xgboost import XGBClassifier
Create Pipelines and initialize classifiers
# pipeline 1 - Naïve Bayes:
clf_nb = Pipeline([('tfidf', TfidfVectorizer()),
('clf', MultinomialNB()),
])
# pipeline 2 - Linear SVC:
clf_lsvc = Pipeline([('tfidf', TfidfVectorizer()),
('clf', LinearSVC()),
])
# pipeline 3 - Logistic Regression:
clf_lgr = Pipeline([('tfidf', TfidfVectorizer()),
('clf', LogisticRegression()),
])
# pipeline 3 - Random Forest Classifier:
clf_rf = Pipeline([('tfidf', TfidfVectorizer()),
('clf', RandomForestClassifier()),
])
# pipeline 4 - XGBoostClassifier:
clf_xgb = Pipeline([('tfidf', TfidfVectorizer()),
('clf', XGBClassifier()),
])
1. Naive Bayes
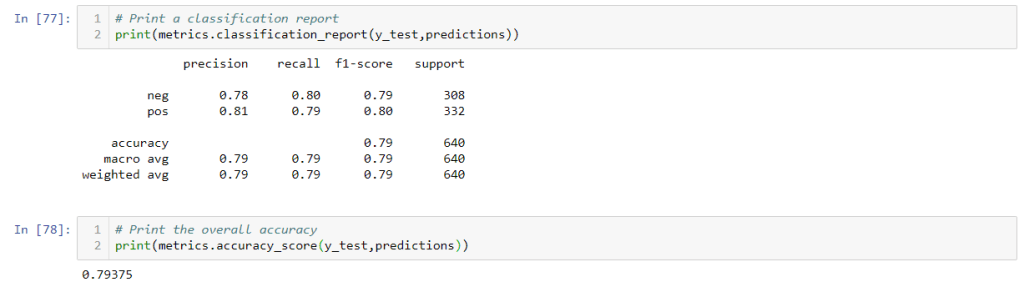
clf_nb.fit(X_train, y_train) # Form a prediction set predictions = clf_nb.predict(X_test) Report the confusion matrix from sklearn import metrics print(metrics.confusion_matrix(y_test,predictions))
# Print a classification report print(metrics.classification_report(y_test,predictions))
Print the overall accuracy print(metrics.accuracy_score(y_test,predictions))

Naïve Bayes gave 76.4% accuracy which is better than the average results for classifying reviews as positive or negative based on text alone. Let’s try other pipelines and see if we can improve it further.





# Use this space to write your own review. Experiment with different lengths and # writing styles. myreview = "A movie I really wanted to love was terrible. \ I'm sure the producers had the best intentions, but the execution was lacking."
print(clf_lsvc.predict([myreview])) # be sure to put "myreview" inside square brackets
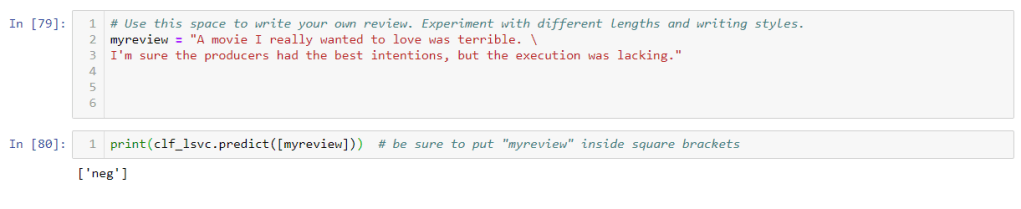
Test the result by writing your own review and run the classifier of your choice by selecting the variable from above pipelines

This all about text classification using tf-idf vectorizer and machine learning algorithms. In my coming post I will be writing about text classification by applying neural networks like RNN, LSTM etc. Stay Tuned !!!
Please do not forget to share your thoughts on the posts and if you have any feedback to improve the content quality or readability please feel free to write in the comments below.
NLP Series: https://ashutoshtripathi.com/category/spacy/
Thank You!!!

I am genuinely thankful to the holder of this web page who has shared this wonderful paragraph at at this place
360DigiTMG
LikeLike
I would like to say that this blog really convinced me to do it! Thanks, very good post.
360DigiTMG
LikeLiked by 1 person
Thank you.
LikeLike