This post is part 2 in the series of frequently asked Machine Learning Interview Questions and Answers. Machine Learning Frequently asked Interview Questions and Answers Part 2
- What is Feature Scaling and why and where it is needed?
- Normalization vs Standardization
- What is the bias-variance trade-off?
- Define the Overfitting problem and why it occurs?
- What are the methods to avoid Overfitting in ML?
1. What is Feature Scaling and why it is needed?
- In general Data set contains different types of variables.
- The significant issue with variables is that they might differ in terms of range of values.
- So the feature with large range of values will start dominating against other variables.
- Models could be biased towards those high ranged features.
- So to overcome this problem, we do feature scaling.
- The goal of applying Feature Scaling is to make sure features are on almost the same scale so that each feature is equally important and make it easier to process by most ML algorithms.
| # | Country | Age | Salary | Purchased |
| 1 | France | 44 | 73000 | No |
| 2 | Spain | 27 | 47000 | Yes |
| 3 | Germany | 30 | 53000 | Yes |
| 4 | Spain | 38 | 62000 | No |
| 5 | Germany | 40 | 57000 | No |
| 6 | France | 35 | 53000 | No |
| 7 | Spain | 48 | 78000 | Yes |
Age Range: 27-48, Salary Range: 47000-78000

| Algorithms | Reasons for applying feature scaling |
| K-means | Use Euclidean Distance measure |
| K-nearest neighbors | Measure the distance between pairs of samples and these distances are influenced by the measurement units |
| Principal Component Analysis (PCA) | Get the features with maximum variance |
| Artificial Neural Network | Apply gradient descent |
| Gradient Descent | Theta calculation becomes faster after feature scaling and the learning rate in the update equation of Stochastic gradient descent is the same for every parameter. |
Note: If an algorithm is not distance-based, feature scaling is unimportant, including Naive Bayes, Linear Discriminant Analysis, and Tree-Based models (gradient boosting, random forest, etc.).
Methods of feature scaling:
- Normalization
- Standardization
2. Normalization and Standardization
2.1 Normalization
- Normalization is also known as min-max normalization or min-max scaling.
- Normalization re scales values in the range of 0-1

| Age | Normalized Age | Salary | Normalized Salary | |
| 44 | 0.80952381 | 73000 | 0.838709677 | |
| 27 | 0 | 47000 | 0 | |
| 30 | 0.142857143 | 53000 | 0.193548387 | |
| 38 | 0.523809524 | 62000 | 0.483870968 | |
| 40 | 0.619047619 | 57000 | 0.322580645 | |
| 35 | 0.380952381 | 53000 | 0.193548387 | |
| 48 | 1 | 78000 | 1 |
2.2 Standardization
- Standardization is also known as z-score Normalization.
- In standardization, features are scaled to have zero-mean and one-standard-deviation.
- It means after standardization features will have mean = 0 and standard deviation = 1.
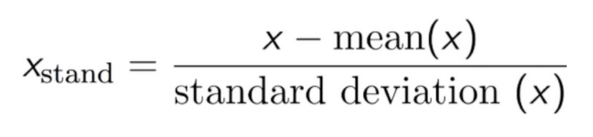
| Age | Standardized Age | Salary | Standardized Salary | |
| 44 | 0.954611636 | 73000 | 1.197306616 | |
| 27 | -1.514927162 | 47000 | -1.278941158 | |
| 30 | -1.079126198 | 53000 | -0.707499364 | |
| 38 | 0.083009708 | 62000 | 0.149663327 | |
| 40 | 0.373543684 | 57000 | -0.326538168 | |
| 35 | -0.352791257 | 53000 | -0.707499364 | |
| 48 | 1.535679589 | 78000 | 1.673508111 |
Normalization vs Standardization
- If you have outliers in your feature (column), normalizing your data will scale most of the data to a small interval, which means all features will have the same scale and hence it will not handle outliers well.
- Standardization is more robust to outliers, and in many cases, it is preferable over Max-Min Normalization.
- Normalization is good to use when you know that the distribution of your data does not follow a Gaussian distribution. This can be useful in algorithms that do not assume any distribution of the data like K-Nearest Neighbors and Neural Networks.
- Standardization, on the other hand, can be helpful in cases where the data follows a Gaussian distribution. However, this does not have to be necessarily true. Also, unlike normalization, standardization does not have a bounding range. So, even if you have outliers in your data, they will not be affected by standardization.
3. What is bias-variance trade-off?
3.1 Bias Error
- Bias are the simplifying assumptions made by a model to make the target function easier to learn.
- Generally, linear algorithms have a high bias making them fast to learn and easier to understand but generally less flexible. In turn, they have lower predictive performance on complex problems that fail to meet the simplifying assumptions of the algorithms bias.
- Low Bias: Suggests less assumptions about the form of the target function.
- High-Bias: Suggests more assumptions about the form of the target function.
- Examples of low-bias machine learning algorithms include: Decision Trees, k-Nearest Neighbors and Support Vector Machines.
- Examples of high-bias machine learning algorithms include: Linear Regression, Linear Discriminant Analysis and Logistic Regression.
3.2 Variance Error
- Variance error is the amount of change in the estimates of the target with the change in training data.
- Logically model will have some variance however it should not change too much from one training data set to the other.
- It means model should be good at picking out the hidden underlying mapping between the input and output variables.
- ML algorithms which have high variance those are influenced by the specifics of the training data.
- Low Variance: Suggests small changes to the estimate of the target function with changes to the training data set. Examples: Linear Regression, Linear Discriminant Analysis and Logistic Regression.
- High Variance: Suggests large changes to the estimate of the target function with changes to the training data set. Examples: Decision Trees, k-Nearest Neighbors and Support Vector Machines.
- Generally, nonlinear machine learning algorithms that have a lot of flexibility have a high variance. For example, decision trees have a high variance, that is even higher if the trees are not pruned before use.
Bias-Variance Trade-Off
- As we understood in previous slides, to have good predictive power or good estimates on target feature, algorithm should have low bias and low variance.
- Linear machine learning algorithms often have a high bias but a low variance.
- Nonlinear machine learning algorithms often have a low bias but a high variance.
- The parameterization of machine learning algorithms is often a battle to balance out bias and variance.
- If you increase the bias, it will start decreasing the variance.
- And if you decrease the variance of model, it will increase the bias. •
Generally low bias and low variance is preferred.


4. What is overfitting and why it occurs?
- In one-liners, when the trained model is not able to generalize the learned behavior on the unseen data, then we say we have encountered the overfitting problem.
- So what does it mean when we say generalize the learned behavior?
- In machine learning, when the model performs well on training data but not giving the near to the same level of accuracy on test data then we say that it is the indication of an overfitted model.
- One more case could be like, your model is performing well on both training as well as testing data but not performing well after the deployment on live data.
- This you can name as the advance form of the overfitting. The reason for this advance level of overfitting is that when we split the original data into train and test they both have similar characteristics. And hence it performed almost similar in training and test data. But after deployment the real data differs in terms of the characteristics and hence due to overfitting, the model could not perform well.

Reasons why Overfitting happens
- When a statistical model describes random error or noise instead of underlying relationship ‘overfitting’ occurs.
- When a model is excessively complex, overfitting is normally observed, because of having too many parameters with respect to the number of training data types.
- In simple terms, when models start learning the noise instead of the actual characteristics then overfitting occurs.
- The possibility of overfitting exists as the criteria used for training the model is not the same as the criteria used to judge the efficacy of a model.
5. Different ways to avoid or overcome Overfitting
. Cross Validation
Split the training data into k-different samples and train the model into k-1 samples and test on the kth sample. Repeat it for all the k samples and in each iteration tune the model.
2. Feature Selection
Apply the feature selection techniques like PCA so that it removes the irrelevant features and hence reduce the noise, one of the causes for overfitting.
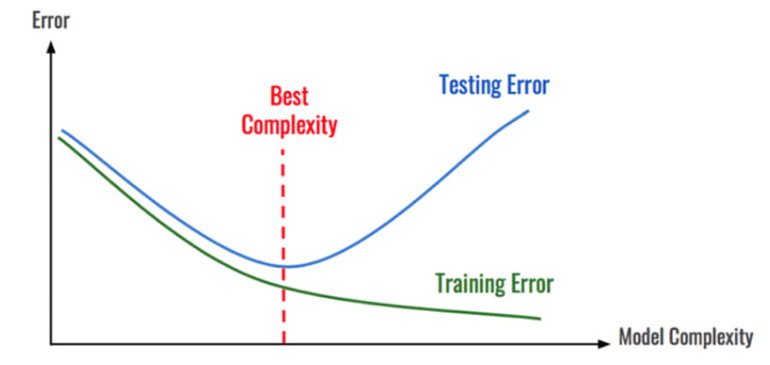
3. Early Stopping
While tuning your model, do testing against the test data, and see if it generalizes well. Stop at the point where it starts increasing the error on the test data.
4. Regularization
Regularization works by assigning different weights to the features based on their importance and impact on the problem we are solving. It also adds the penalty term to the cost function to manage the data bias.
5. Ensemble Techniques
- Bagging
- Boosting
Recommended Articles:

5 comments