Multicollinearity occurs in a multi linear model where we have more than one predictor variables. So Multicollinearity exist when we can linearly predict one predictor variable (note not the target variable) from other predictor variables with significant degree of accuracy. It means two or more predictor variables are highly correlated. But not the vice versa means if there is low correlation among predictors then also multicollinearity may exist.
In more generic terms:
When the amount of information among predictor variables is not all independent then we say that multicollinearity exists.
Hence by removing multicollinearity, we can get a reduced set of predictors which contained most of the information. “stepAIC” function do this all for us, it removes multicollinearity as well as produces the final optimal set of predictors which contained most of the information and also which build the significant fit model.
Various questions related to multicollinearity which interviewer frequently asked are as following:
- What is Multicollinearity?
- How Multicollinearity is related to correlation?
- Problems with Multicollinearity.
- Best way to detect multicollinearity in the model.
- How to handle/remove Multicollinearity from the model?
We will try to understand each of the questions in this post one by one.
Multicollinearity vs Correlation
Correlation coefficient tells us that by which factor two variables vary whether in same direction or in different direction. in other words correlation coefficient tells us that whether there exists a linear relationship between two variables or not and absolute value of correlation tells how strong the linear relationship is. correlation coefficient zero means there does not exist any linear relationship however these variables may be related non linearly.
High correlation means there exist multicollinearity however if correlation value is low then also multicollinearity may exist hence correlation is not the conclusive evidence for the existence of the multicollinearity. The reason behind this is that correlation is always determined between two variables, however multicollinearity exist when one predictor variable can be predicted with the help of other set of predictor variables. This is what is meant by “when not all information contained by a variable is independent means some of that information can be determined by other set of predictor variables.”
Lets understand this with the help of an example. we can draw correlation plot using cor(data frame) function, where all variable should be numeric.

In the above correlation plot, darker and bigger circle represents high correlation between variables.

In the above matrix, correlation between “disp” and “cyl” is 90.28% which is very high. It means when we increase cyl value, hp value that is horse power also increases which is true also. We are using 10 variables to predict the mpg value but it looks like whatever the information contained by “disp” variable also contained by cyl variable so there is no reason to include both the variables in out prediction model, however we can choose only one.
Problems with Multicollinearity
When multicollinearity exists in model, it could not calculate regression coefficient confidently. Means there could be multiple options for regression coefficient which will not ave statistically any meaning.
Let’s take a very simple example just to understand this point. So what could be the linear equations to predict the y value from below table?
| x1 | x2 | y |
| 0 | 0 | 0 |
| 1 | 1 | 2 |
| 2 | 2 | 4 |
| 3 | 3 | 6 |
Possible options would be:
- y = x1 + x2 ?
- y= 2×1 ?
- y=2×2 ?
- y=2.5×1 – .5×2 ?
So the same case occurs when we have multicollinearity. Now lets understand it with real problem set.

Best way to detect multicollinearity
Stepwise Regression prevents multicollinearity problem to a great extent, however the best way to know if multicollinearity exist is by calculating variance inflation factor (VIF).
We calculate VIF for each of the predictor (independent variable). In this approach we completely neglect target variable temporary. And try to predict each predictor variable itself with the help of remaining set of predictors.
Suppose there are three predictors x1, x2, x3. then regression equations will be like below:
- x1 = b1 + b2x2 + b3x3
- x2 = b1 + b2x1 + b3x3
- x3 = b1 + b2x1 + b3x2
Each of the above equation will give back the R-squared value. hence VIF will be
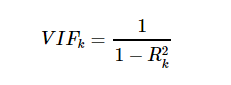
So general rule is if VIF > 10 OR R-squared is > 0.90 then severe Multicollinearity exist. Again in the mtcars data set if we run vif(linearmodel) then we get the following result:

So we can say variables “cyl”, “disp”, “wt”, “gear” and “carb” causes multicollinearity.
So what next shall we immediately remove those variables and start with model building. The answer is no, this is not the whole story. Although Multicollinearity exist but still removing those variable blindly will have impact on the accuracy. So here comes stepAIC which select final set of variables by considering both model performance as well as multicollinearity issue. You may refer my article on stepAIC here to know more on it with an example.
So that’s all, about the Multicollinearity. Hope it gives you good understanding of what is Multicollinearity and how to handle it. In case you have any doubts/ideas feel free to share using the comment section below.
Related Articles on Machine Learning:

A valuable article here but I couldn’t understand what Rk^2 exactly means. And how do we calculate Rk^2. Could you please elaborate?
LikeLike