Problem Statement:
A sport hosting company would like to decide to host a cricket match between India and South Africa based on whether data. Weather data that is available has attributes like outlook, temperature, humidity and wind. And has a decision variable how many hours were played. We need to build a decision tree model to predict based on weather data how many hours will be played?
Data:
| Outlook | Temperature | Humidity | Windy | Hours Played |
| Sunny | Hot | High | FALSE | 25 |
| Sunny | Hot | High | TRUE | 30 |
| Overcast | Hot | High | FALSE | 46 |
| Rainy | Mild | High | FALSE | 45 |
| Rainy | Cool | Normal | FALSE | 52 |
| Rainy | Cool | Normal | TRUE | 23 |
| Overcast | Cool | Normal | TRUE | 43 |
| Sunny | Mild | High | FALSE | 35 |
| Sunny | Cool | Normal | FALSE | 38 |
| Rainy | Mild | Normal | FALSE | 46 |
| Sunny | Mild | Normal | TRUE | 48 |
| Overcast | Mild | High | TRUE | 52 |
| Overcast | Hot | Normal | FALSE | 44 |
| Rainy | Mild | High | TRUE | 30 |
Solution:
The ID3 algorithm can be used to construct a decision tree for regression type problems by replacing Information Gain with Standard Deviation Reduction – SDR
A decision tree is built top down from a root node and involves partitioning the data into subsets that contain instances with similar values mean homogeneous data.
Here, standard deviation is used to calculate the homogeneity of a numerical sample (target variable). If the numerical sample (more specific target variable) is completely homogeneous with respect to independent variable (we check for each independent variable separately), then its standard deviation is zero.
Will use the same concept of standard deviation and will check on each split how much reduction in standard deviation is there, and the node (independent variable) which has more reduction in standard deviation that will be declared as a decision node. (In first iteration this node will be called as root node). If not clear at this point, no worries, follow the complete article and I am sure it will be clear.
Reduction in Variance or Standard Deviation Reduction (SDR):
Variance tells us the average distance of all data points from the mean point. Standard deviation is just the square root of the variance. As variance is calculated in squared unit and hence to come up a value having unit equal to the data points, we take square root of the variance and it is called as Standard Deviation.

So, what is standard deviation reduction. So basically, first we calculate the standard deviation of the target variable. And then calculate the weighted standard deviation of target with respect to each independent variable. Then take a difference. And this is known as reduction in standard deviation.
Step 1: First will calculate the total standard deviation with respect to target variable:

Coefficient of variation is ratio of standard deviation divide by the average value and take the percentage of it. This will be used as the stopping criteria for further split. Will discuss this point at the time of using it so it will be clearer there.
Step 2: will calculate SDR with respect to independent variables and decide on root node, decision nodes and leaf nodes.
Deciding the root node
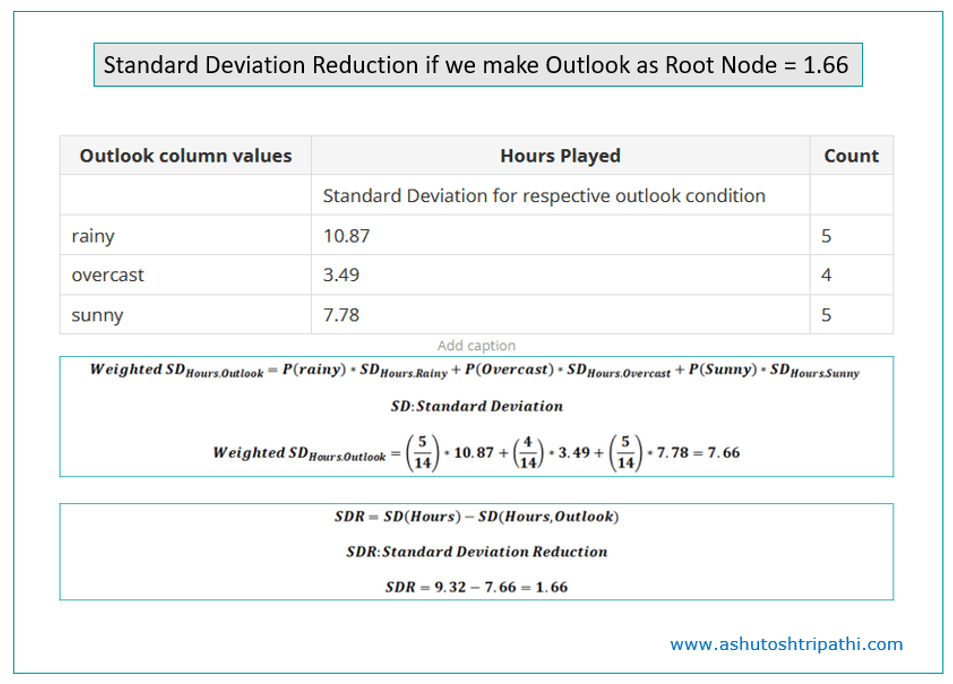
SDR for Outlook:
SDR for Temperature: (use same formulas as mentioned above)

SDR for Humidity:

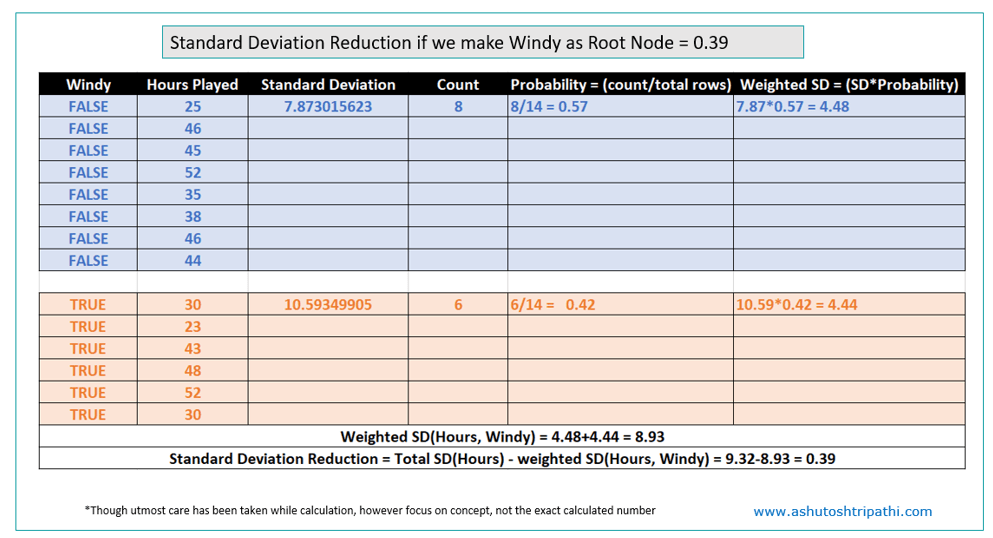
SDR for Windy:
- SDR (Hours, Outlook) = 1.66
- SDR (Hours, Temperature) = 0.39
- SDR (Hours, Humidity) = 0.09
- SDR (Hours, Windy) = 0.39
Outlook has most reduction in standard deviation hence outlook will be the root node.

For the next node we need some termination criteria like when to stop splitting. Hence, we consider coefficient of variance as one of the termination criteria and for example can set CV = 10% as a threshold. So, if we have CV > 10% then further splitting is required else will stop there. Or we can also set threshold on number of data points (rows) if less than or equal to 3 then no split required.
And the prediction at leaf node will be the average of that branch.
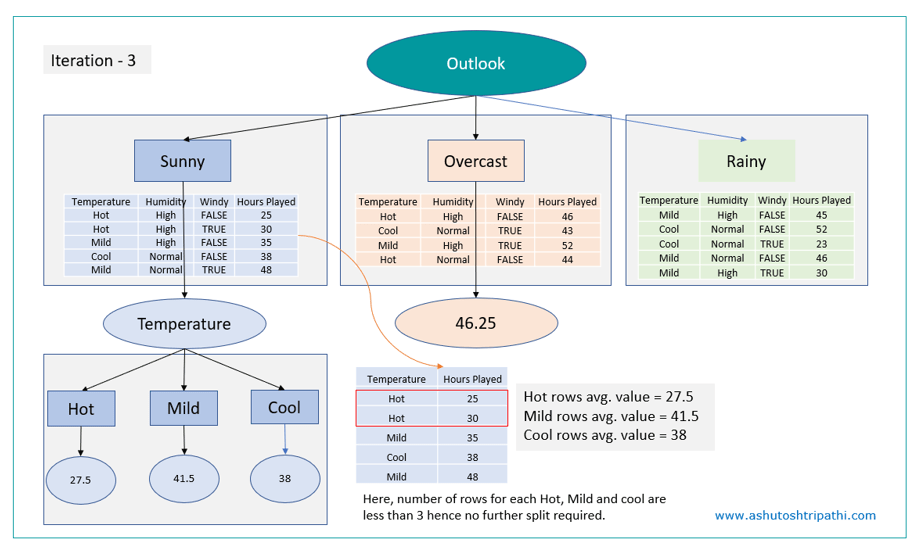
Here Sunny and Rainy nodes need further splitting as both have CV > 10% however Overcast does not need splitting as CV for overcast <= 10%.
Average value of overcast branch = 46.25 will be the prediction at overcast leaf.

Now will repeat the same SDR check for data filtered for Sunny and Rainy to get other decision nodes and subsequent leaf nodes.
SDR check for Sunny data rows:

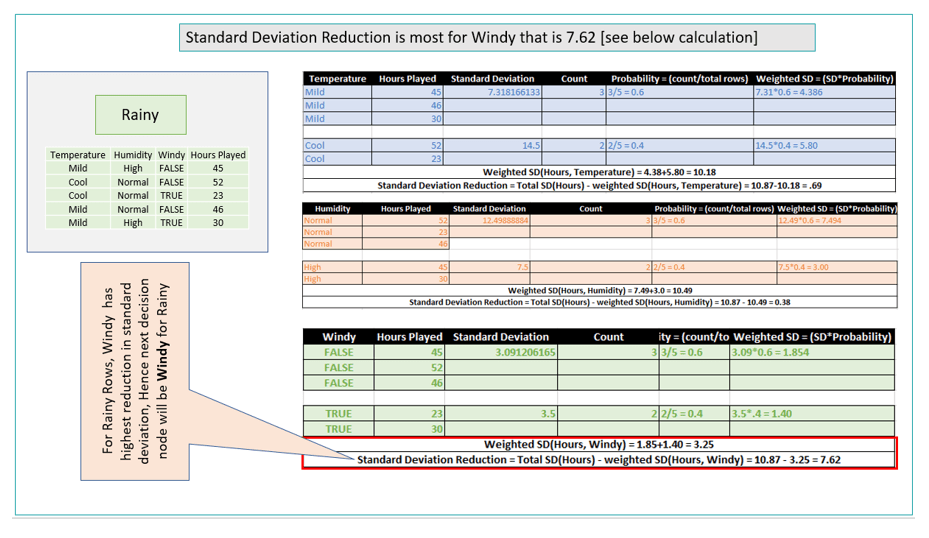
SDR check for Rainy Data rows:
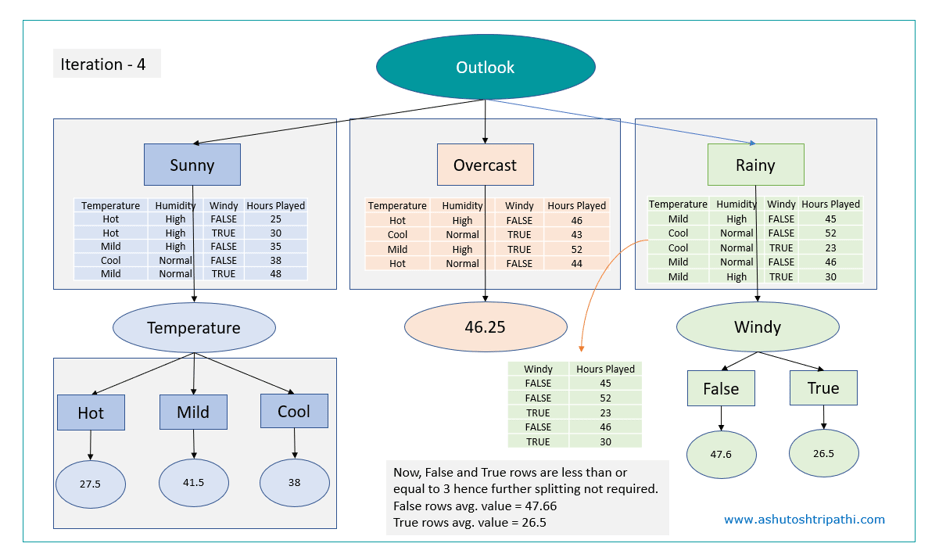

Decision Tree Interpretation:
- If outlook condition is sunny and temperature is mild then prediction on number of hours match can be played is 41.5 hours irrespective of other conditions.
- If outlook is overcast then irrespective of other conditions, prediction is 46.25 hours.
- If outlook is rainy then if it is windy then prediction is 26.5 hours and if it is not windy then prediction is 47.6 hours.
If you have any doubts, then feel free to get in touch with me:
Thank You!!!

💐 Wish You A Happy New Year ! 🎉
LikeLike
Thank you very much for the wishes. Also wishing you a very happy new year.
LikeLiked by 1 person