Let me start with simple question. Can we compare Mango and Apple? Both have different features in terms of tastes, sweetness, health benefits etc. So comparison can be performed between similar entities else it will be biased. Same logic applies to Machine Learning as well. Feature Scaling in Machine Learning brings features to the same scale before we apply any comparison or model building. Normalization and Standardization are the two frequently used techniques of Feature Scaling in Machine Learning.
Key takeaways from this post:
- Understand what is Feature Scaling?
- Why and how high range of features impact model performance?
- Different techniques to scale the features
- Normalization vs Standardization
- When to use which feature scaling technique?
- At what phase of Data Preprocessing feature scaling to be applied? Before data split or after split?
- ML Algorithms sensitive to Feature Ranges and require Feature Scaling
What is Feature Scaling?
- In general Data set contains different types of variables having different magnitude and units (kilograms, grams, Age in years, salary in thousands etc).
- The significant issue with variables is that they might differ in terms of range of values.
- So the feature with large range of values will start dominating against other variables.
- Models could be biased towards those high ranged features.
- So to overcome this problem, we do feature scaling.
- The goal of applying Feature Scaling is to make sure features are on almost the same scale so that each feature is equally important and make it easier to process by most ML algorithms.
Why and how high range of features impact model performance?

in the above table we see that both Age and Salary have different range of values. So when we train a model it might give high importance to salary column just because the high range of values. However it could not be the case and both columns have equal or near to equal impact on target variable which could be based on age and salary whether a person will buy a house or not. So in case of buying a house both age and salary have equal importance. So here we need to do the feature scaling.
Another example could be when we want to identify k-nearest neighbors then high range of features will be separated out far from other features and they will tell that they are not similar and they don’t belong to the neighbors. which could not be the case again.
Lets understand above points by applying some mathematics.
In machine learning everything is measured in terms of numbers and when we want to identify the nearest neighbors, similarity or dissimilarity of features then we calculate the distance between features and based on distances we say two features are similar or not. Similar means if we consider a feature with respect to the target variable then similarity mean how much a feature impacts the target variable.
Lets understand this distance thing with an example. So there are many method to calculate distance here we will take Euclidean distance.

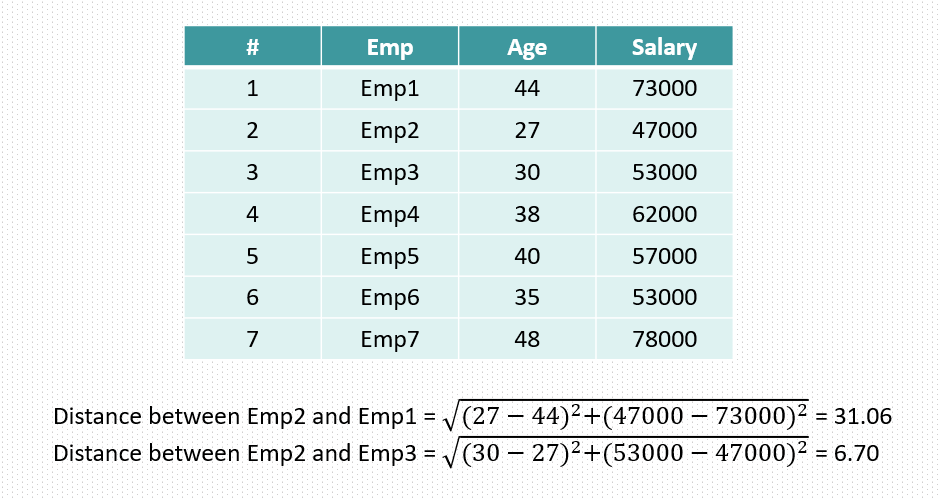
Now see if the task is to identify the neighbors of emp2 then by above distance we can say emp3 is more close to emp2 as emp2 and emp3 share less distance between them. but think now if we simply increase the salary number then this distance will increase and then it will imply that emp2 and emp3 are not similar. So idea behind feature scaling is that value range should not impact the feature behavior. When we want to do the comparison between two entities we should first bring them in same page or same level or same scale then only we can do the comparison.
Also another great intuition is comparison become easy or more stable when we compare smaller and same scale values than the larger range and different scale values.
Feature Scaling Techniques
In Machine Learning there are two mostly used feature scaling techniques.
- Normalization
- Standardization
Normalization
- Normalization is also known as min-max normalization or min-max scaling.
- Normalization re-scales values in the range of 0-1


Standardization
- Standardization is also known as z-score Normalization.
- In standardization, features are scaled to have zero-mean and one-standard-deviation.
- It means after standardization features will have mean = 0 and standard deviation = 1.
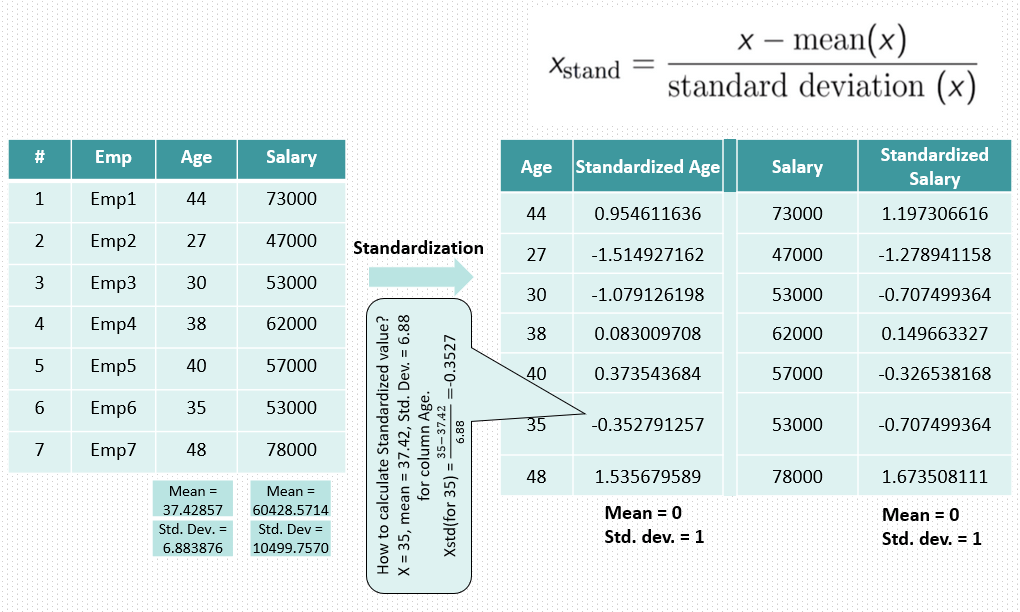
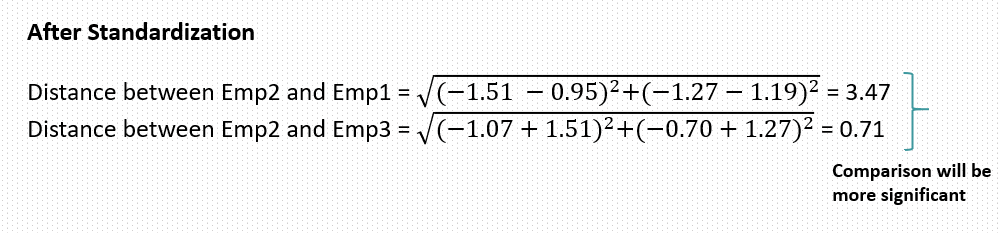
Normalization vs Standardization
- If you have outliers in your feature (column), normalizing your data will scale most of the data to a small interval, which means all features will have the same scale and hence it will not handle outliers well.
- Standardization is more robust to outliers, and in many cases, it is preferable over Max-Min Normalization.
- Normalization is good to use when your data does not follow a Normal distribution. This can be useful in algorithms that do not assume any distribution of the data like K-Nearest Neighbors and Neural Networks.
- Standardization, on the other hand, can be helpful in cases where the data follows a Normal distribution. However, this does not have to be necessarily true. Also, unlike normalization, standardization does not have a bounding range. So, even if you have outliers in your data, they will not be affected by standardization.
When to do Feature Scaling? After Train-Test Split or Before?
In general, feature scaling should be done after split to avoid data leakage.
If we do scaling before the split, then training data will also have information about test data which will make it anyway perform good in test data but model might not perform good when it comes to actual prediction on unseen data.
Data Leakage:
When information from outside the training data set is used to create the model. This can allow the model to learn or know something that it otherwise would not know and in turn invalidate the estimated performance of the model being constructed.
Preferred way:
- Split data
- Perform scaling on training
- Build model on training set
- Use the scaling parameters mean / variance from the training set to scale the testing data separately. Lets take example of standardization where we use standard deviation of training data to scale the features. So to scale test data use the same standard deviation and scale test data (than calculating standard deviation for testing data and use it.)
- Then test on testing set.
ML Algorithms which need feature Scaling

Note: If an algorithm is not distance-based, feature scaling is unimportant, Algorithms which do not need feature scaling are Naive Bayes, Linear Discriminant Analysis, and Tree-Based models (gradient boosting, random forest, etc.).
Linear and Logistic Regression algorithms as well need feature scaling as they use gradient descent method.
Feature scaling is one of the important step which need to be considered during data preprocessing. When I say it need to be considered, I mean at least it requires a thought to be given like whether to scale the feature or not. And this decision depends upon the type of Machine Learning algorithm you are going to use. Distance based machine learning algorithms are highly sensitive to feature ranges and if we do not scale the features then there are high chances model might become biased towards high range features.
So this is all about Feature Scaling in Machine Learning. If you like the article, you might also like to watch my videos on Machine Learning concepts and Interview preparation. Below is the link to my ML YouTube channel, If you like then do not forget to like, subscribe and share.
Recommended Articles on ML:

One comment